Elasticsearch y MongoDB son dos tecnologías populares en el ecosistema de NoSQL, pero tienen propósitos y arquitecturas distintas. Elasticsearch es un motor de búsqueda y análisis distribuido, mientras que MongoDB es una base de datos orientada a documentos.
Arquitectura y Modelo de Datos
Elasticsearch
Elasticsearch utiliza un modelo de índices, documentos y shards. Almacena los datos en un formato optimizado para la búsqueda, basado en Apache Lucene.
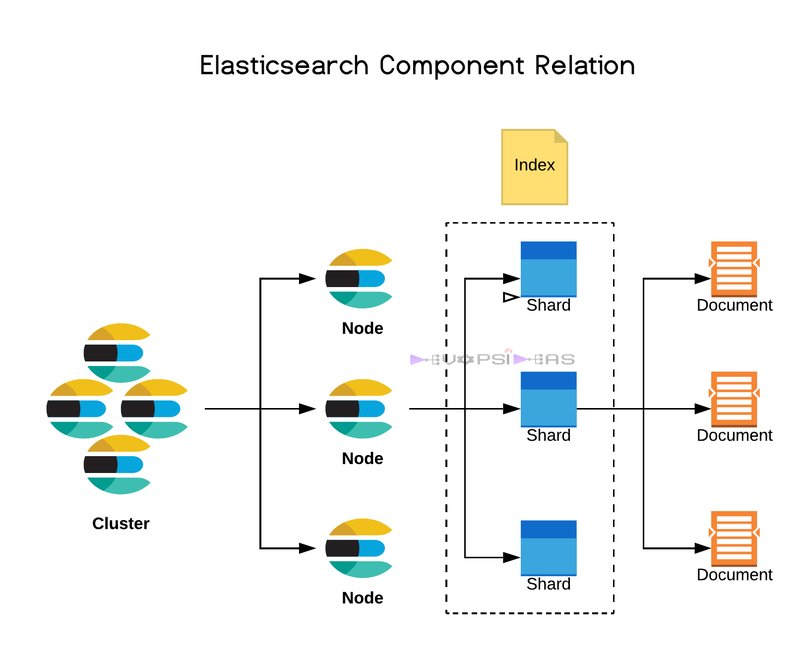
- Índices y Documentos: Elasticsearch organiza los datos en índices, que son similares a las tablas de MySQL. Cada índice contiene múltiples documentos, que son las unidades básicas de datos, estructurados en formato JSON.
- Shards y Réplicas: Los índices se dividen en shards, que son fragmentos de datos distribuidos entre los nodos del clúster. Cada shard puede tener réplicas para garantizar alta disponibilidad y tolerancia a fallos.
- Nodos y Clúster: Un clúster de Elasticsearch está compuesto por varios nodos, que son instancias de Elasticsearch. Cada nodo puede tener un rol específico (master, data, ingest) para optimizar la búsqueda y la gestión de datos.
- Apache Lucene: Es el motor subyacente que maneja la indexación y búsqueda, proporcionando estructuras como árboles invertidos y segmentación de documentos para búsqueda rápida.
- Query DSL: Un lenguaje de consulta específico que permite realizar búsquedas avanzadas, agregaciones y análisis en tiempo real sobre los datos.
MongoDB
MongoDB almacena los datos en documentos BSON (una extensión de JSON) dentro de colecciones, permitiendo una estructura flexible y jerárquica.
- Colecciones y Documentos: MongoDB organiza los datos en colecciones (similares a las tablas en MySQL) y almacena los registros como documentos BSON..
- Replica Sets: Conjuntos de réplicas que proporcionan alta disponibilidad. Un Replica Set tiene un nodo primario que maneja las escrituras y múltiples nodos secundarios que sincronizan los datos.
- Sharding: MongoDB distribuye datos entre múltiples servidores a través de un proceso llamado sharding.
Esto permite escalar horizontalmente al distribuir la carga de trabajo en múltiples shards. - Nodos y Clústeres: MongoDB utiliza un conjunto de nodos que pueden ser primarios (manejan escrituras y lecturas) o secundarios (sólo lecturas). Esto proporciona redundancia y balanceo de carga.
- Motor de Consultas: MongoDB utiliza un motor de consultas JSON que soporta operaciones CRUD, agregaciones, y búsqueda de texto básico, aunque no es tan potente para búsquedas complejas como Elasticsearch.
Comparación de Arquitecturas
En cuestion de escalabilidad, ambas soportan el escalado horizantal con los clusters. Sin embargo, Elasticsearch esta más optimizado para manejar grandes volumenes de datos a través de su distribución de shards.
Para la tolerancia de fallas MongoDB utiliza Replica Sets que requiere configuraciones más especificas a diferencia de Elasticsearch que distribuye las réplicas automáticamente. Hablando de consistencia, Elasticsearch opera bajo el principio de consistencia eventual, priorizando la rapidez de las búsquedas, mientras tanto MongoDB puede configurarse para ofrecer distintos niveles de consistencia, lo que lo hace más adaptable a diversas necesidades.
Comparación de los modelos de datos
MongoDB permite almacenar estructuras de datos jerárquicas complejas. Cada documento es un objeto de tipo JSON con pares clave-valor, lo que proporciona una representación natural para muchos tipos de datos.
Elasticsearch también almacena datos en formato JSON, pero se centra más en la búsqueda y recuperación eficientes que en las estructuras de datos complejas.
Mientras que el modelo de MongoDB es adecuado para aplicaciones con datos diversos y en evolución, la simplicidad de Elasticsearch a la hora de manejar datos planos y desnormalizados la convierte en la opción preferida para aplicaciones de búsqueda intensiva
Comparación del lenguaje de consulta
MongoDB emplea un potente lenguaje de consulta que permite diversos criterios y admite la indexación para mejorar el rendimiento de las consultas. Estas caracteristicas lo hace adecuado para una amplia gama de aplicaciones.
Elasticsearch, fue diseñado para la búsqueda, ofrece funciones de consulta avanzadas, como la búsqueda de texto completo, el filtrado y la navegación por facetas.
La velocidad y eficiencia de Elasticsearch a la hora de recuperar información relevante de grandes conjuntos de datos lo distinguen en los casos de uso orientados a la búsqueda. Sin embargo, las capacidades de consulta de MongoDB, combinadas con su flexibilidad en el modelado de datos, lo convierten en un fuerte contendiente para aplicaciones con diversos requisitos de consulta.
Escalabilidad
MongoDB realiza un escalado horizontal, lo que permite la distribución de los datos en cluster. Esto garantiza que, a medida que crecen los datos, se pueden añadir servidores adicionales para mantener el rendimiento.
La naturaleza distribuida de Elasticsearch proporciona escalabilidad de forma inherente, lo que lo hace idóneo para aplicaciones que exigen un acceso rápido a grandes cantidades de datos. Su capacidad para manejar grandes cargas de búsquedas concurrentes y operaciones de indexación lo convierte en la opción perfecta para escenarios con cargas de trabajo demandantes.
La desventaja dominante es que Elasticsearch requiere una licencia de paga para utilizar clusters, a diferencia de MongoDB que ofrece estas caracteristicas avanzadas sin requerir licencia.
Consistencia
MongoDB soporta transacciones ACID, asegurando la consistencia de los datos en escenarios donde múltiples operaciones necesitan ser atómicas. Esto lo hace adecuado para aplicaciones donde mantener la integridad de los datos es crítico.
Elasticsearch, por el contrario puede experimentar inconsistencias temporales entre nodos por el modelo de consistencia eventual.
Es un punto a tener en cuenta si el nivel de consistencia es requerido por sus aplicaciones . Mientras que MongoDB asegura una consistencia inmediata, el modelo de consistencia eventual de Elasticsearch podría ser aceptable para ciertos casos de uso.
Rendimiento e indexación
MongoDB emplea varias estrategias de indexación para optimizar el rendimiento de las consultas. Se pueden crear índices en campos específicos, garantizando una recuperación eficiente de los datos en función de los requisitos de la consulta. Esto permite a MongoDB proporcionar respuestas rápidas y específicas a las consultas, especialmente en escenarios con estructuras de datos complejas.
Elasticsearch, al ser principalmente un motor de búsqueda, destaca en la indexación y búsqueda de grandes volúmenes de datos basados en texto. Su arquitectura de índice invertido permite búsquedas rápidas, por lo que es ideal para aplicaciones que exigen capacidades de búsqueda casi en tiempo real. Cabe destacar el rendimiento de Elasticsearch en el manejo de datos dinámicos no estructurados, lo que contribuye a su popularidad en el análisis de registros y casos de uso similares.
Seguridad y Gestión
MongoDB ofrece sólidas funciones de seguridad, como mecanismos de autenticación, control de acceso basado en roles y cifrado en reposo, que ayudan a proteger los datos frente a accesos no autorizados y garantizan el cumplimiento de las normas de seguridad. Estas funciones ayudan a proteger los datos de accesos no autorizados y garantizan el cumplimiento de las normas de seguridad.
Elasticsearch también ofrece funciones de seguridad completas, que permiten a los administradores controlar el acceso a los datos y las acciones dentro del sistema. Características como el cifrado TLS, el control de acceso basado en roles y el registro de auditoría contribuyen a una implementación segura de Elasticsearch.
Resumen
| Característica |
Elasticsearch |
MongoDB |
| ¿Para qué sirve? |
Para buscar y analizar información rápidamente, especialmente en textos largos. |
Para almacenar y gestionar datos de forma flexible y organizada. |
| ¿Cómo organiza los datos? |
Usa índices (listas de información) y documentos (datos en formato de texto). |
Usa colecciones (agrupaciones de datos) y documentos (parecidos a registros). |
| ¿Cómo funciona? |
Divide los datos en fragmentos (shards) que se distribuyen entre varios servidores. |
También divide los datos, pero con más control sobre cómo se distribuyen. |
| ¿Cómo se hacen las búsquedas? |
Tiene un sistema muy avanzado para hacer búsquedas rápidas y específicas. |
Permite buscar y gestionar datos de manera más flexible pero menos enfocada en búsqueda. |
| ¿Cómo maneja grandes volúmenes de datos? |
Es ideal para manejar grandes cantidades de datos que requieren búsquedas rápidas. |
Se adapta bien a grandes volúmenes, pero no es tan rápido en búsquedas complejas. |
| ¿Qué pasa si un servidor falla? |
Los datos se copian automáticamente en otros servidores para evitar pérdida. |
Tiene una copia de seguridad, pero requiere más configuración. |
| Seguridad |
Control de acceso para usuarios y cifrado de datos (protegido). |
También ofrece control de acceso y protección de datos. |
| Licencia |
Algunas funciones avanzadas requieren pagar una licencia. |
Las funciones avanzadas son gratuitas. |
| ¿Cuándo usarlo? |
Ideal para proyectos que necesitan buscar y analizar mucha información rápidamente. |
Ideal para proyectos que necesitan organizar muchos tipos de datos diferentes. |