¿Que son los indices?
Los índices en MySQL permiten localizar y devolver registros de una forma sencilla y rápida. Son especialmente útiles cuando queremos buscar elementos de entre los millones y hasta billones de registros que puede contener una tabla en un momento dado. Cuando no usamos índices, a veces podemos percibir que MySQL tarda demasiado en responder una consulta.
Los indices funcionan como una Guía telefónica. Si buscaras en especifico un apellido que empiece con la letra Z, simplemente debes abrir el apartado del final de la guia, pues se encuentran ordenados los apellidos con inicial Z.
En este caso, los indices generan pequeñas tablas | punteros que permiten ordenar el contenido de una tabla.
El problema ...
En nuestra aplicación, de repente, el presentar datos en una tabla se volvió lento, y muchísimo más el realizar filtros sobre la misma.
Pensamos que habíamos solucionado los problemas de lentitud al crear llaves foráneas y filtrar sobre estas, pues ya estaban "indexadas" en automático.
Pero no, una cosa es crear indices, y otra es utilizarlos correctamente.
Midamos los tiempos.
Para este ejemplo, tendremos una tabla como la siguiente:
+--------------------------+----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| fecha_emision | date | NO | MUL | NULL | |
| fecha_vencimiento | date | NO | MUL | NULL | |
| fecha_pago | datetime | NO | MUL | NULL | |
| estado | smallint(5) unsigned | NO | MUL | NULL | |
| sub_total | decimal(15,2) | NO | | NULL | |
| descuento | decimal(15,2) | NO | | NULL | |
| impuestos | decimal(15,2) | NO | | NULL | |
| total | decimal(15,2) | NO | | NULL | |
| empresa_id | int(11) | YES | MUL | NULL | |
| zona_id | int(11) | NO | MUL | NULL | |
| estado_factura_id | int(11) | YES | MUL | NULL | |
| tipo_id | int(11) | YES | MUL | NULL | |
+--------------------------+----------------------+------+-----+---------+----------------+
Los campos que terminan en "id" son llaves foráneas. Esto se puede obtener ejecutando esta query: DESCRIBE <your_table></your_table>
Cuando hacíamos consultas a esta tabla filtrando por las columnas "estado_factura_id", "empresa_id" y "tipo_id", tomaba demasiado tiempo el traer hasta 300 registros. La query se veía como la siguiente:
SELECT `wisp_factura_factura`.`id`,
...
FROM `wisp_factura_factura`
...
WHERE (
`wisp_factura_factura`.`estado_factura_id` = 2
AND `wisp_factura_factura`.`empresa_id` = 1
AND `wisp_factura_factura`.`fecha_pago` BETWEEN
'2022-09-01 00:00:00' AND '2022-09-30 23:59:59'
AND NOT ( `wisp_factura_factura`.`tipo_id` = 2
AND `wisp_factura_factura`.`tipo_id` IS NOT NULL ) )
ORDER BY `wisp_factura_factura`.`id_factura` DESC;
Primera vez: 373 rows in set (13.05 sec) |
Segunda vez: 373 rows in set (13.03 sec)
Podemos observar que obtener 373 registros tardaba más de 13 segundos. Un tiempo bastante amplio por hacer filtros que obtenga pocos datos.
Para los clientes, este tiempo se volvía eterno, se presentaron muchos reportes a Soporte Técnico, por lo que procedimos a buscar la manera de solucionarlo.
Hicimos diferentes pruebas para hacer las querys mas rápidas temporalmente, movimos las consultas a un servidor de replica que tenia bastante capacidad, lo cual mejoro el tiempo de las consultas, también modificamos la query para excluir ciertos campos, pero no era suficiente, seguía siendo lento.
Investigando en internet y con ayuda de aplicaciones externas que optimizan base de datos llegamos a lo siguiente.
¿Qué esta haciendo MySQL con mi Query?
Encontramos que la palabra reservada EXPLAIN antes de la query podría brindarnos información sobre lo que MySQL estaba haciendo al obtener la información de la tabla. Algo como lo siguiente:
EXPLAIN SELECT `wisp_factura_factura`.`id`,
...
FROM `wisp_factura_factura`
...
WHERE (
`wisp_factura_factura`.`estado_factura_id` = 2
AND `wisp_factura_factura`.`empresa_id` = 1
AND `wisp_factura_factura`.`fecha_pago` BETWEEN
'2022-09-01 00:00:00' AND '2022-09-30 23:59:59'
AND NOT ( `wisp_factura_factura`.`tipo_id` = 2
AND `wisp_factura_factura`.`tipo_id` IS NOT NULL ) )
ORDER BY `wisp_factura_factura`.`id_factura` DESC;
La palabra "EXPLAIN" simplemente se agrega antes de la query.
Esto devuelve la informacion de la siguiente forma:
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: wisp_factura_factura
partitions: NULL
type: index_merge
possible_keys: wisp_factura_factura_empresa_id_7e69b086_uniq,wisp_factura_factura_empresa_id_43ac50a0_uniq,wisp_factura_factura_fecha_pago_d54270ae_uniq,wisp_factura_factura_e8f8b1ef,wisp_estado_factura_id_4d1450bc_fk_wisp_factura_estadofactura_id,wisp_factura_fac_tipo_id_16d1f4df_fk_wisp_factura_tipofactura_id
key: wisp_factura_factura_e8f8b1ef,wisp_estado_factura_id_4d1450bc_fk_wisp_factura_estadofactura_id
key_len: 5,5
ref: NULL
rows: 117639
filtered: 8.61
Extra: Using intersect(wisp_factura_factura_e8f8b1ef,wisp_estado_factura_id_4d1450bc_fk_wisp_factura_estadofactura_id); Using where; Using filesort
Vamos a explicar los resultados mas relevantes de esta consulta.
type: index_merge es el tipo de indice que el optimizer de MySQL, a través de ciertos algoritmos, decidió utilizar para que la query fuera la mas optima.
possible_keys son todos los indices que el optimizer tomo en cuenta para poder realizar la consulta.
key es el indice que el optimizer utilizo para realizar la consulta.
La query nos explica que hacia algo con los indices, pero eso no explica el porque es tan lento. Para comprender mejor la consulta, debimos consultar los indices que esta tabla tenia.
Para ello simplemente nos apoyamos de la siguiente query:
SHOW INDEX FROM <YOUR_TABLE>
Obtuvimos algo como lo siguiente:
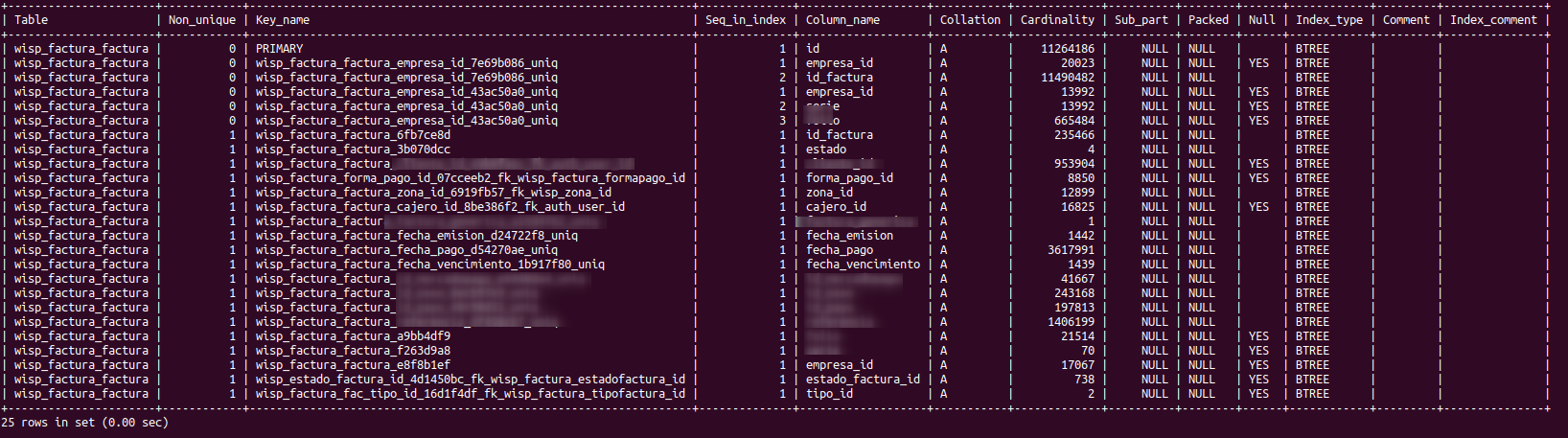
Con esto se pudo entender lo siguiente:
- El optimizer de MySQL es quien se encarga de que la query este lo mas optimizada posible y para ello hace uso de los indices.
- Existen diferentes type's al momento de hacer la consulta. La que la query EXPLAIN muestra que para este caso se utilizó un index_merge, es decir una consulta en base a varios indices.
- Los indices utilizados fueron:
- wisp_factura_factura_e8f8b1ef: Relacionado a la columna "empresa_id"
- wisp_estado_factura_id_4d1450bc_fk_wisp_factura_estadofactura_id: Relacionado a la columna "estado_factura_id"
- La tabla de indices muestra mucho mas indices que los mostrados en "possible_keys"
Estas preguntas nos llevaron a investigar el funcionamiento del index_merge, y nos encontramos que a muchas personas les ha ocurrido el mismo problema que a nosotros, y han llegado a lo mismo. Que el optimizer de MySQL utilice un indice compuesto para hacer la consulta, vuelve todo mas lento. Mas info
¡Solución!
Decidimos probar con todos los indices, para ver cual era el mas eficiente para realizar la consulta. Para ello utilizamos la sentencia "USE INDEX(<index-name>)" de MySQL, el cual sugiere al optimizer que indice utilizar en la consulta.
Con ello logramos reducir DRASTICAMENTE el tiempo de la consulta.
La consulta quedo de la siguiente forma:
SELECT `wisp_factura_factura`.`id`,
...
FROM `wisp_factura_factura`
USE INDEX (`wisp_factura_factura_e8f8b1ef`)
...
WHERE (
`wisp_factura_factura`.`estado_factura_id` = 2
AND `wisp_factura_factura`.`empresa_id` = 1
AND `wisp_factura_factura`.`fecha_pago` BETWEEN
'2022-09-01 00:00:00' AND '2022-09-30 23:59:59'
AND NOT ( `wisp_factura_factura`.`tipo_id` = 2
AND `wisp_factura_factura`.`tipo_id` IS NOT NULL ) )
ORDER BY `wisp_factura_factura`.`id_factura` DESC;
Primera vez: 373 rows in set (0.84 sec) |
Segunda vez: 373 rows in set (0.81 sec)
De esta forma, lo que antes tardaba 13 Segundos, toma ahora menos de 1 segundo. Un gran cambio en el tiempo de la Consulta.
En el ambiente productivo hicimos uso de la sentencia "FORCE_INDEX" la unica diferencia con "USE_INDEX" es que la primera obliga al optimizer a utilizar el indice que se le asigna, y el segundo le sugiere al optimizer el utilizarlo, pero el optimizer puede llegar a ignorarlo.